

Training Data, Fine-Tuning, LoRAs — The Path to a Studio-Trained AI
The base model knows the internet's average taste. It does not yet know yours.

The base image model that ships out of Black Forest Labs, Stability AI, Google, Midjourney, or any other model lab is not born with a studio’s judgement. It is trained or adapted on vast mixtures of image-text material: filtered public web data, synthetic data, licensed or proprietary material, human preference signals, safety filtering, and vendor decisions we cannot fully audit from outside.[1] It is a generalist — a statistical compromise around what has appeared often enough, cleanly enough, and legibly enough in the visual data ecology. Which is why every architect who has worked with one for more than a week has the same private complaint. The model produces something competent. It does not produce something that belongs to the studio. It produces, with eerie consistency, the visual register of an Australian renovation magazine merged with Pinterest merged with ArchDaily.

This is article five of a seven-part series. Article 3 opened the diffusion engine; Article 4 introduced embeddings — the joint coordinate system in which language and image share an address. This article is about what changes when a studio decides not merely to prompt the system, but to bias it in its own direction. The technical primitives — fine-tuning, LoRAs, IP-Adapter, ControlNet — are no longer exotic. They are accessible to any studio willing to spend a focused weekend learning the operational grammar. The literacy is not in deciding whether to touch these tools. It is in knowing what each path costs, what it buys, and which one matches the studio’s actual ambition. I will call this studio-flavoured generation — generation in which the base model is pushed, either through training or inference-time conditioning, toward the visual signature of a specific practice.

What the base model actually saw
The current frontier image-generation families — FLUX.2, Stable Diffusion 3.5, Imagen 4, Midjourney V7, and the V8/V8.1 alpha testing track — sit on web-scale and proprietary-scale image training ecosystems.[2] The precise datasets behind closed commercial systems are not public. That matters. So the safer statement is not: we know exactly what the model saw. The safer statement is: the model’s behaviour reflects the visual gravity of the data ecology it was trained on, filtered through whatever proprietary curation, synthetic data, licensing, ranking, and safety systems the vendor applied.
Public datasets show the scale. LAION-5B contains 5.85 billion CLIP-filtered image-text pairs. COYO-700M contains roughly 747 million image-text pairs.[1] Stability AI’s own Stable Diffusion 3.5 documentation describes training on a wide variety of data, including synthetic data and filtered publicly available data.[1] But the scale is not the architecturally interesting fact. The composition is.
The publicly visible part of that ecology is the open web. And the open-web centre of gravity is not neutral. Dense coverage of buildings written about by Western design press. Dense coverage of styles that circulate on Instagram, Pinterest, Dezeen, ArchDaily, Behance, and the rendering economy. Dense coverage of interiors photographed for aspiration, not habitation. Dense coverage of categories that have their own SEO machinery. Thin coverage of vernacular South Asian housing, regional Karnataka detailing, Omani souk typology, lime-wash and oxide-floor traditions, small-town thresholds, working-class climatic intelligence, and the built environments that did not become algorithmically rewarded image categories.
This article takes this further on the ethics. The operational consequence is enough for now. The model knows what its data ecology knows. Where that ecology is dense, the model is fluent. Where that ecology is sparse, the model is unreliable. The fix is not always a longer prompt. The fix is often to give the model denser signal or new territory.
Fine-tuning, in plain terms
Fine-tuning continues a model’s training on a smaller, more specific dataset. The base model has already learned a vast distribution of visual possibility. Fine-tuning nudges that distribution toward a new body of material. Depending on the method, you may update the full model, train a small adapter, or teach the system a new concept handle. The outcome is similar in practice: where the model used to land on internet-average modernism, it starts landing closer to whatever you trained or conditioned it on.
Done in full, this is heavy work. Full model fine-tuning means modifying a large fraction of the model’s weights — the billions of numbers encoding what it has learned. That demands serious compute, careful data preparation, evaluation discipline, and people who know how to read failure before it becomes an expensive habit. For most studios, full fine-tuning is not the first move. It may not be any move.
The breakthrough that changed the economics is Low-Rank Adaptation — LoRA — published by Hu et al. in 2021 and now widely used across the open diffusion ecosystem.[3] Instead of modifying every weight, you freeze the base model and train a small set of additional low-rank weights that sit alongside it. At inference, the LoRA biases the model’s behaviour without requiring a new full model to be trained from scratch. The patch is usually a portable file — often tens to a few hundred megabytes, depending on the base model, rank, target layers, and training setup. You can swap LoRAs in and out. You can stack them. You can version them. You can train one without becoming a model lab. This is what I mean by the LoRA economy — Hugging Face training scripts, the PEFT library underneath, community checkpoints, internal studio adapters, and marketplaces where thousands of LoRAs circulate.[3] LoRA did not make training free. It made customisation small enough to become operational. For image AI, that is the important shift.
Two related techniques are worth knowing. DreamBooth fine-tunes a model to recognise a specific subject from a small number of reference images — classically around three to five, though production workflows may use more if the subject is varied.[4] Textual Inversion does something lighter. It teaches the model a new word or token that maps to a visual concept, without modifying the full model itself. The word becomes a navigation handle inside the embedding space that I described in the earlier articles.[4] For a studio’s overall signature, LoRA remains the operational default in the open-weight diffusion ecosystem in 2026.
Vendor-hosted fine-tuning APIs are the managed cousin of the same impulse. Black Forest Labs, for example, offers a FLUX Pro fine-tuning API for customising FLUX with user-supplied images.[5] The strategic question is not only whether the model can be tuned. It is where the tuned asset lives, who owns it, who can export it, who can retrain it, and who is legally allowed to use the material that shaped it.
The no-training paths
Two more primitives are underused in architectural practice. They are also, in most cases, the first thing to try.
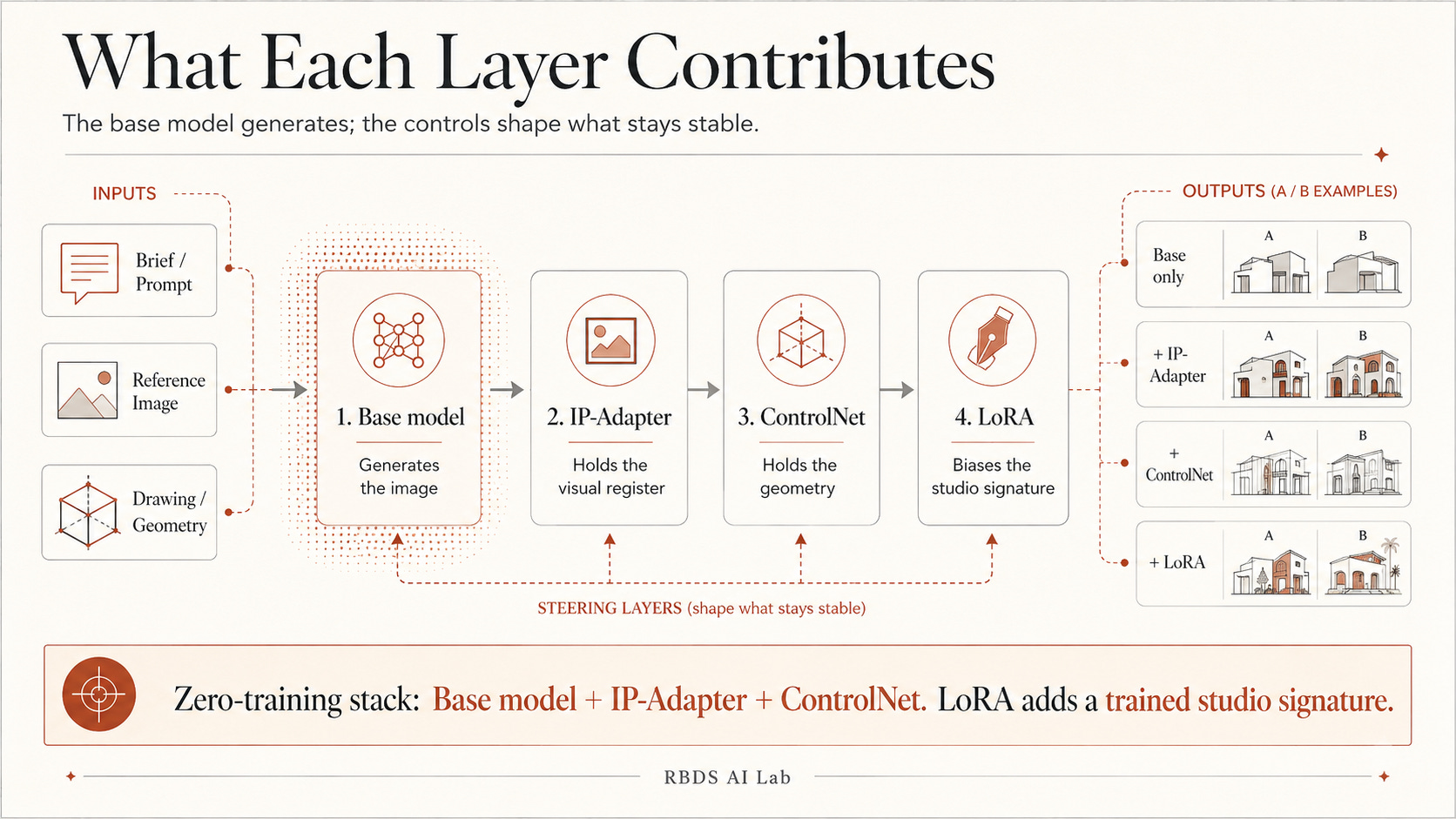
IP-Adapter is an image-prompt adapter: a small neural network, around twenty-two million parameters, that lets you feed a reference image into the generation process as a strong steering signal — without training the base model.[6] You curate five or ten hero images. You load the adapter or use a workflow that supports image-reference conditioning. At every generation, one reference image enters alongside the prompt. The output carries more of the reference’s visual register without the base model being modified. Zero training time. An afternoon to test. In closed tools (like Midjourney), the same operational idea often appears as reference-image, style-reference, or image-guidance controls. In open diffusion workflows, IP-Adapter is the clean primitive to understand.
ControlNet is the other inference-time primitive, arguably the most important one for architects using open diffusion systems. Published by Zhang et al. in 2023, ControlNet conditions the generation loop on a structural input — a depth map, edge map, pose skeleton, segmentation mask, or Canny edge extracted from a drawing.[7] For architects, that structural input can be a plan, section, elevation, massing outline, façade rhythm, or depth cue. ControlNet does not magically understand a plan the way an architect understands a plan. It does something narrower and more useful. It gives the diffusion process a structure it must negotiate with. This remains one of the most reliable ways to keep walls, openings, outlines, and spatial proportions closer to where you put them while changing materiality, atmosphere, time of day, or visual language. With it, the architect holds geometry steady and iterates on register.
Together, IP-Adapter and ControlNet form what I would call the zero-training stack — studio-flavoured generation produced entirely at inference time. For most studios, this delivers much of the practical value of a custom LoRA at a fraction of the effort. Most studios should exhaust the zero-training paths first.
What each layer contributes: the base model generates; the LoRA biases the signature; ControlNet holds the geometry; IP-Adapter or reference-image conditioning holds the register.
A small studio in Mysuru, three available paths
A small studio in Mysuru has built, over a decade, a recognisable language. Kota stone floors. Oxide-red ground plates. Board-form concrete. Lime-wash on upper masses. A signature eave overhang across six houses. A stair-section detail recurring across most of the work. The principal has decided that base FLUX outputs do not represent the practice and is asking what it would take to make the model speak in the studio’s accent.
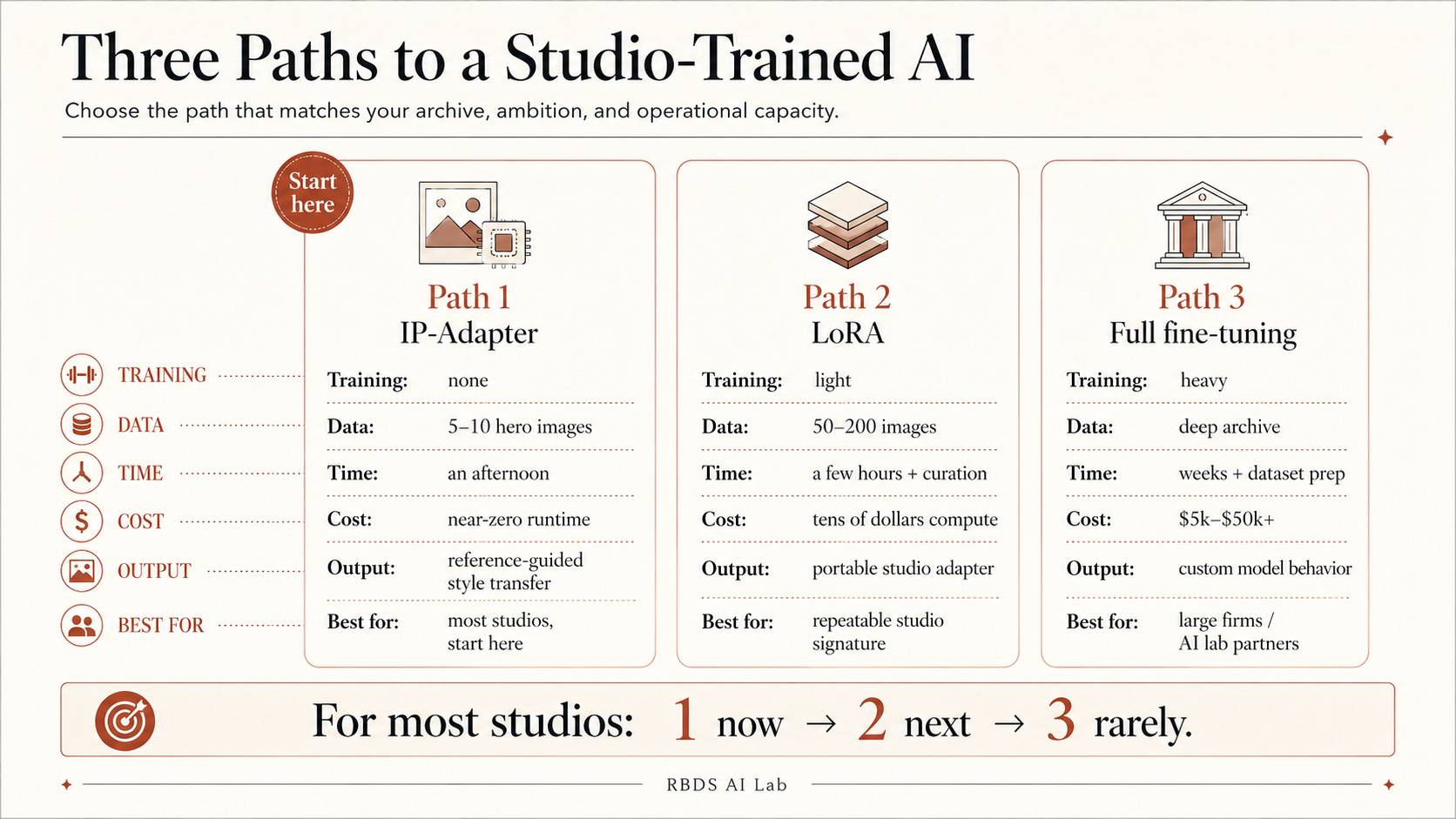
There are three viable paths, sitting at very different points on the cost / time / expertise / control matrix.
Path 1 — IP-Adapter, no training. The team curates five to ten hero photographs — strongly composed, legally usable, and carrying the studio’s material palette clearly. At every generation, one image is fed in as a reference alongside the prompt. The output begins to carry the studio’s signature: oxide ground, Kota tonality, lime-wash, heavy eaves, shaded thresholds, the particular darkness of a Mysuru afternoon. No training. No new model. No long dataset preparation. Cost: essentially zero beyond runtime and tool access. Deploy: an afternoon. The limitation is important. The signature carries best when the reference is close to the target in typology, lighting, and compositional logic. A courtyard-house reference transfers better into another courtyard house than into a hospital lobby. A stair detail transfers better into another sectional interior than into an urban masterplan aerial. Cross-typology transfer is possible, but less reliable. This is where most small studios should be immediately. Not because it is the most powerful path. Because it has the least regret.
Path 2 — LoRA, light training. The team curates fifty to two hundred high-resolution photographs across the body of work. Not every beautiful photograph belongs in the dataset. The selection has to be deliberate: enough repetition for the model to learn the studio’s signature, enough variation for it not to overfit, enough caption quality for the model to understand what matters. The team writes captions in the studio’s own vocabulary: “oxide-red ground plate,” “low lime-wash mass,” “Kota stone threshold,” “deep shaded verandah,” “board-form concrete stair wall,” “monsoon eave.” The captions matter because they teach the model what distinctions the studio itself considers meaningful. Plans and elevations can be included, but with caution. They do not automatically teach architectural intelligence unless the workflow is designed to use drawings as training targets, paired conditions, or captioned context. Otherwise they are better used through ControlNet or as reference material during prompting.
The team rents a GPU or uses a hosted fine-tuning workflow. As of June 2026 public pricing, RunPod lists 80GB A100 options around $1.39 to $1.49 per hour, while Lambda lists A100 instances at $1.99 per hour for 40GB and $2.79 per hour for 80GB.[8] Training time is usually a few hours, plus testing, failed runs, caption revisions, and retraining. Compute cost is often tens of dollars, not thousands. The real cost is curation, captioning, rights clearance, and evaluation. Output: a portable LoRA file, often tens to a few hundred megabytes, that can be combined with the base model to produce renders carrying the studio’s signature across future briefs. The LoRA becomes studio IP — version-controlled, access-controlled, retrained as the archive grows, and audited before external use. This is where studio-flavoured generation crosses from inference trick into trained asset.
Path 3 — Full fine-tuning, heavy. Full fine-tuning or serious domain adaptation means modifying a large part of the model itself, not merely adding a small steering layer. This is no longer a weekend exercise. Cost: not $100. With data preparation, specialist labour, evaluation, failed runs, compute, and security protocol included, $5,000 to $50,000+ is a more honest planning range. Time: weeks of experiments, and often months of dataset preparation. Expertise: someone who can read loss curves, diagnose overfitting, debug pipeline failures, evaluate model collapse, and explain to the studio why a beautiful result may still be a bad model. Output: a model that does not merely apply the studio’s signature, but behaves as if the signature is part of its default imagination. That is powerful. It is also dangerous if the dataset is weak, the legal rights are unclear, or the studio does not know how to evaluate what has changed. Realistic only for large studios with serious AEC-AI ambitions, strong internal archives, or a partnership with an AI lab. For the Mysuru studio, this is a five-year horizon. For a hundred-architect firm with a research arm, it is a current strategic decision.
Three paths, five operational dimensions. The choice is not whether — it is which.
The conventional framing — train your own AI, or stay with the defaults — is symmetric and wrong. The right question is asymmetric: which path matches the studio’s ambition, archive, and operational capacity? For almost every small-to-mid studio in 2026: Path 1 immediately, Path 2 within six months if the archive and rights are clean, Path 3 not at all. For a forty-architect firm with a publishable archive: Path 1 immediately, Path 2 within the quarter, and a serious conversation about hosted fine-tuning, internal LoRA governance, and longer-term domain adaptation. For a single-author practice: Path 1 first. Path 2 only when there is enough owned work and a repeatable visual thesis worth encoding.
The published architectural record remains thin. Practitioners such as Tim Fu, Hassan Ragab, and Ismail Seleit have made AI-assisted architectural imagery and design workflows visible in public culture, but full technical disclosure of training stacks remains rare.[9] Studio Tim Fu’s Lake Bled Estate is one of the clearer public built-environment examples because reporting describes AI involvement in concept, detail, and heritage-led iteration. But even there, the public material does not provide a reproducible training stack.[10] The infrastructure is maturing. The disclosure norms have not caught up.
What this returns to the architect
The studio that owns ten years of project archives owns a training corpus. It may not yet own the awareness that this is what it owns. The first move is not to fine-tune. The first move is to recognise that the archive — photographs, plans, elevations, captions, details, material schedules, presentation boards, site studies — is now strategic infrastructure with a use it did not have before.
The architect’s role inside this stack does not shrink. It relocates. Curating the reference set is a design decision. Captioning the training data is a design decision. Captions written in the studio’s own vocabulary produce a model that can respond to the distinctions the studio itself cares about. Auditing the output is a design decision. Not “does it look good?” That is too weak. The better question is: would the studio put its name to this?
The vendor pitch is trained AI in six hours. The actual work is not six hours. The actual work is the archive audit, the curation, the captioning, the IP clearance, the photographer agreement, the client-data permission, the internal policy on whether live client projects may enter training sets, the disclosure question when a concept image was AI-developed, the authorship question when the studio’s signature sits inside a portable file an ex-employee could walk out with, and the access-control question when a LoRA becomes as sensitive as a fee proposal or drawing template. The technical stack is the easy part. The protocol around it is the work.
For the hidden costs underneath every model — and what every architect should refuse to look away from — read Part 6.
The three paths are teachable, but not as a weekend trick or a tool tutorial. They need a different kind of architectural literacy: how to read a model’s bias, how to curate a studio archive, how to caption work in the studio’s own language, how to protect authorship, and how to decide where AI belongs inside a real design process. That is the larger project behind RBDS AI Lab.
We are building Logika as the learning layer of that project — a place for architects, designers, students, educators, and studios trying to enter the age of artificial intelligence without surrendering architectural judgement to the machine. Courses, workshops, essays, and learning programmes will sit there as a growing field guide for this transition: not AI as spectacle, but AI as a design intelligence that must be understood, questioned, trained, and governed.
If this series is the map, Logika is where the practice begins.
Sources
Sources
[1] Public image-text dataset scale and model-data caveat: LAION-5B is the clearest public benchmark for the scale of open image-text training data, with 5.85 billion CLIP-filtered image-text pairs.
LAION. “LAION-5B: A New Era of Open Large-Scale Multi-Modal Datasets.” March 31, 2022.
https://laion.ai/laion-5b-a-new-era-of-open-large-scale-multi-modal-datasets/
[2] Current model-version caveat: Midjourney’s official documentation is used here mainly to support the V8 / V8.1 alpha wording, so the article does not overstate V8 as a stable default model.
Midjourney. “Version.”
https://docs.midjourney.com/hc/en-us/articles/32199405667853-Version
[3] LoRA and parameter-efficient fine-tuning: Hu et al.’s original LoRA paper describes freezing pretrained weights and injecting trainable low-rank matrices instead of fully fine-tuning the model.
Hu, Edward J., et al. “LoRA: Low-Rank Adaptation of Large Language Models.” arXiv:2106.09685, 2021.
https://arxiv.org/abs/2106.09685
[4] DreamBooth and subject-specific tuning: DreamBooth is the key source for explaining subject-driven image-model tuning from a small number of reference images.
Ruiz, Nataniel, et al. “DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation.” arXiv:2208.12242, 2022.
https://arxiv.org/abs/2208.12242
[5] Vendor-hosted fine-tuning: Black Forest Labs describes FLUX Pro Finetuning as a way to customise FLUX with user-supplied images and concepts.
Black Forest Labs. “Announcing the FLUX Pro Finetuning API.” January 16, 2025.
https://bfl.ai/announcing-the-flux-pro-finetuning-api/
[6] IP-Adapter: The official IP-Adapter repository describes it as a lightweight image-prompt adapter with roughly 22 million parameters, used to add image-reference guidance without training the base model.
Tencent AI Lab. “IP-Adapter.”
https://github.com/tencent-ailab/IP-Adapter
[7] ControlNet: Zhang et al.’s original paper describes ControlNet as a method for adding spatial conditioning controls to pretrained text-to-image diffusion models.
Zhang, Lvmin, Anyi Rao, and Maneesh Agrawala. “Adding Conditional Control to Text-to-Image Diffusion Models.” arXiv:2302.05543, 2023.
https://arxiv.org/abs/2302.05543
[8] GPU pricing: RunPod’s public pricing page is used as a representative cloud-GPU pricing reference. Pricing changes and varies by availability, configuration, storage, and region.
RunPod. “GPU Cloud Pricing.”
[9] Public AI-architecture practitioners: AEC Magazine’s profile of Hassan Ragab is used as a concise public reference for AI-assisted architectural imagery entering architectural discourse.
AEC Magazine. “Midjourney architecture: Hassan Ragab, conceptual AI artist.” October 12, 2022.
https://aecmag.com/ai/midjourney-architecture-hassan-ragab-conceptual-ai-rtist/
[10] Studio Tim Fu / Lake Bled Estate: Dezeen’s article is used as the compact public reference for Lake Bled Estate as an AI-assisted architectural project.
Dezeen. “Tim Fu uses AI as ‘design collaborator’ for Slovenian housing development.” April 3, 2025.
https://www.dezeen.com/2025/04/03/lake-bled-estate-tim-fu-ai/
I’m Sahil Tanveer of the RBDS AI Lab, where we explore the evolving intersection of AI and Architecture through design practice, research, and public dialogue. If today’s post sparked your curiosity, here’s where you can dive deeper:
Read my book – Delirious Architecture: Midjourney for Architects, a 330-page exploration of AI’s role in design → Get it here
Join the conversation – Our WhatsApp Channel AI in Architecture shares mind-bending updates on AI’s impact on design → Follow here
Learn with us – Our online course AI Fundamentals for Lighting Designers is power-packed with 17+hrs of video content through 17 lessons → Enroll Here
Explore free resources – Setup guides, tools, and experiments on our Gumroad
Watch & listen – Our YouTube channel blends education with architectural art
Discover RBDS AI Lab – Visit our website
Speaking & events – I speak at conferences and universities across India and beyond. Past talks here
📩 Enquiries: sahil@rbdsailab.com | Instagram