

What AI Actually Is — A Probability Engine, Not a Computer
The mental model most architects are still using is the reason the tool keeps frustrating them.


Most of the frustration architects report with AI is not a tool problem. It is a category mistake. The architect, trained for two decades to operate deterministic software — CAD, BIM, Revit, Photoshop, V-Ray — sits down in front of ChatGPT or Midjourney and asks the same kind of question they would ask of AutoCAD: what rule is the software following, and why didn’t it follow it correctly this time?
The question has no useful answer.
This is article one of a seven-part series. Before we can talk about tokens, diffusion, embeddings, training data, or agents, the underlying category has to be corrected. AI is not a faster computer. It is a different kind of system, and most of the daily friction — “it gave me a different answer the second time,” “it ignored my constraint” — is the architect mid-translation between two cognitive registers without knowing it.
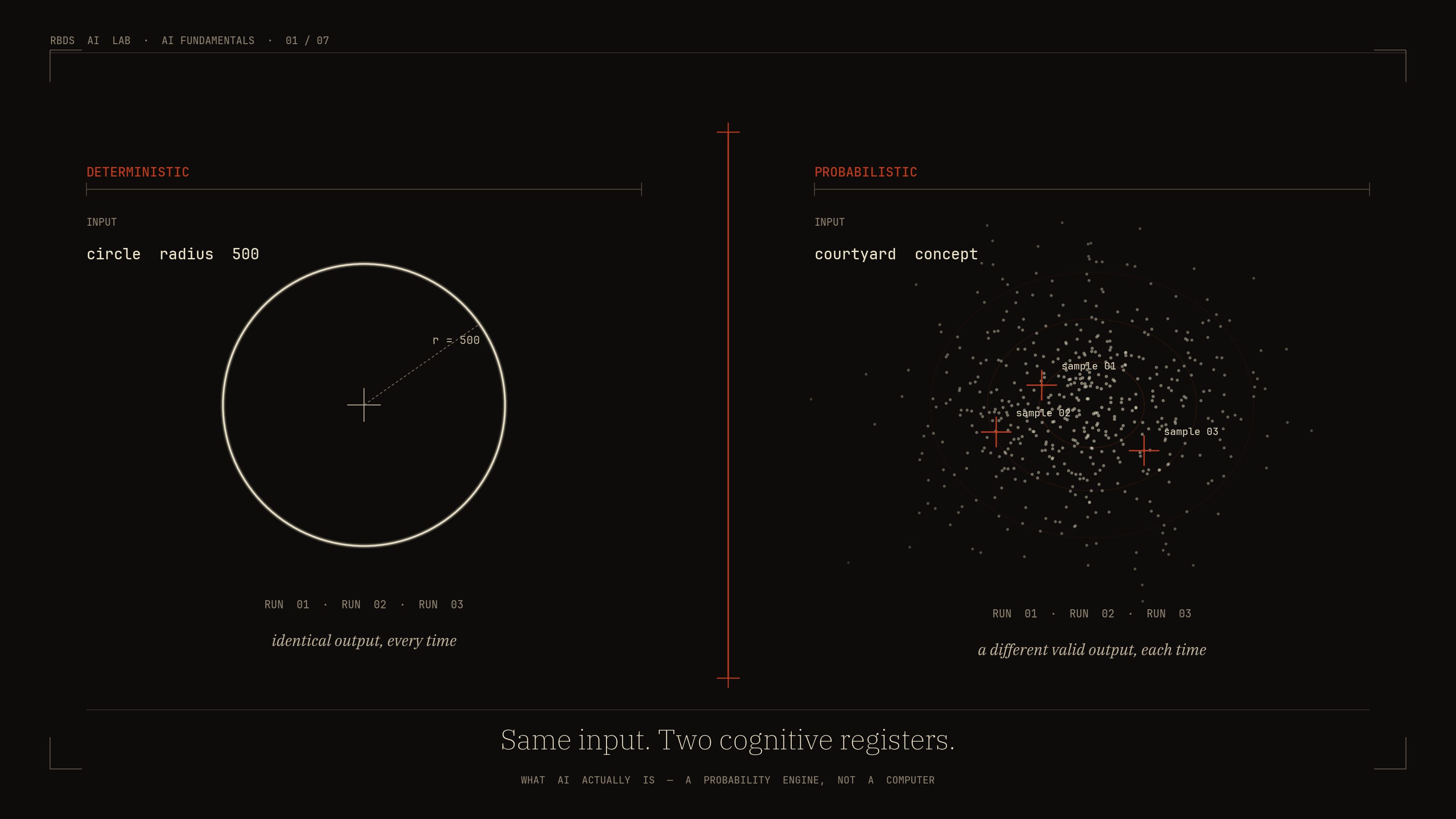
The category that broke
For thirty years, design software has been deterministic. Same input, same output. Type LINE 0,0 to 1000,500 into AutoCAD and you get the exact same line, today and ten years from now. The software computes a defined function over inputs and returns a defined output.
This is the cognitive register architects have been trained inside. The instinct it produces is specific: when something goes wrong, look for the rule. The bug is in the parameter, the layer, the unit, the constraint. Fix the input, the output stabilises. The relationship between architect and software is one of operating.
Generative AI is not in this register. It does not compute a function. It samples from a distribution.
What “model” actually means
When an engineer says “the model,” they don’t mean software the way an architect does. A model is a function that maps an input to a probability distribution over possible outputs. It does not produce an answer. It produces a landscape of plausible answers, weighted by likelihood, and a separate step — sampling — picks one.
When you type a prompt into ChatGPT and receive a response, this is what happened: the model computed, for every possible next word the system knows, the probability that this word is what should come next given everything that came before. A sampler reached into that distribution and drew one word. The process repeated, conditioned each time on what had been written so far. The reply you see is one walk through a landscape of probabilities. A different walk, taken a second later under slightly different conditions, would have been almost as plausible.
This is why two runs of the same prompt give two different answers. It is not a bug. It is the system behaving exactly as its architecture says it will — in the default case, without explicit reproducibility controls. [1]
The CAD-conditioned instinct reads this as malfunction. Why did it change? What did I do differently? The honest answer is: nothing. The system is non-deterministic by design. Asking why two outputs differ is like asking why two proposals from a junior architect differ when you brief them on Monday and again on Wednesday.
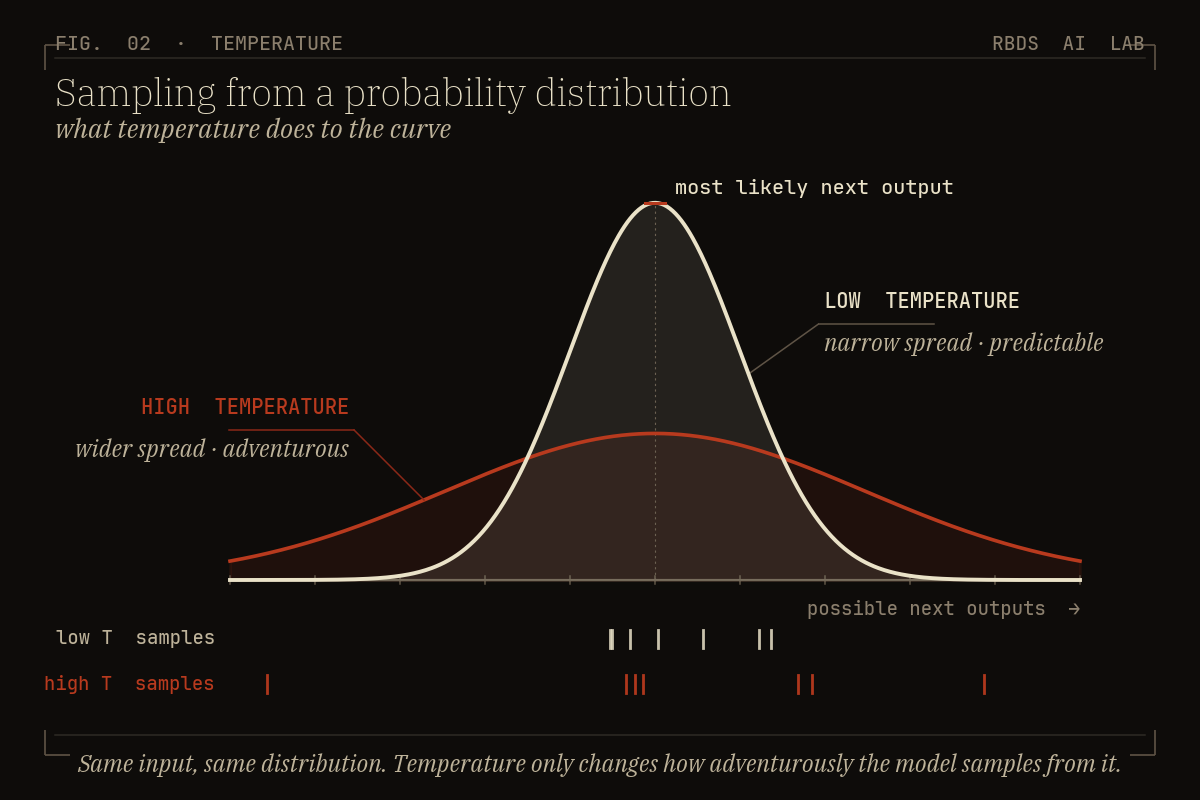
Sampling, and the knob nobody told you exists
The sampler — the part of the system that decides which word, pixel, or token to draw — has a knob called temperature. Low temperature pulls the sampler toward the highest-probability options: predictable, conservative, repetitive. High temperature lets it reach further down the distribution: more diverse, more surprising, occasionally incoherent. A related knob, top-p, does roughly the same job through a different mechanism.
You do not need the math. You need the intuition: the same brief, fed to the same model, will produce a wider or narrower spread of outputs depending on how the sampler is configured. When an image model gives you twelve variations on a courtyard, you are looking at twelve samples drawn from one distribution under one set of sampler settings. Re-roll the seed and you get twelve more, all defensible, none “correct” in CAD’s sense.
The architect’s reflex — “which is the right one?” — breaks down here. There is no right one. There is a spread of plausible answers, and the new job is to evaluate the spread.
The four rings, and why ChatGPT is not “AI”

The vocabulary has collapsed. “AI” is used as if it meant one thing. It refers to four nested categories — and treating them as one is why the conversation has become incoherent.
Artificial Intelligence is the outer ring — any system that performs tasks associated with cognition. A 1996 chess engine is AI. A spam filter is AI. So is ChatGPT. The category is wide.
Machine Learning sits inside it: systems that learn patterns from data rather than executing rules a human wrote.
Deep Learning sits inside that: machine learning using neural networks with many layers. Almost all of the AI you actually encounter today — image classifiers, translation, voice transcription — is deep learning.
Generative AI sits in the innermost ring: deep learning systems that produce new content rather than classifying existing content. ChatGPT, Claude, Gemini, Midjourney, FLUX, Stable Diffusion — all generative AI.
A new layer is being constructed on top of all this — agents — which wrap these models with tool-use scaffolding, memory, and the ability to act in the world. We get to that in Part 7.
When someone says “AI is biased” or “AI hallucinates” or “AI will replace architects,” the first useful question is: which ring? The answer for a 1996 expert system is different from the answer for a 2026 multimodal frontier model. Treating them as one thing is how the public conversation became unworkable.
Two valid courtyards from one brief
A worked example, because the abstraction will not land alone.
An architect submits the same brief to ChatGPT twice — a tight Bengaluru plot, a small residential courtyard, four constraints on setbacks, climate, budget. Monday morning. Monday afternoon.
Run 1 returns a concept emphasising shading strategy for the south façade. The reasoning organises itself around the climate constraint. The courtyard is placed to optimise for cross-ventilation.
Run 2 returns a concept emphasising spatial sequencing — entry, threshold, courtyard, main living. The reasoning organises itself around the experiential constraint. The courtyard is placed to optimise for the procession of arrival.
Both are professionally defensible. Neither is wrong. Neither is the “correct” answer, because the brief did not have a correct answer — it had a distribution of defensible interpretations, and two samples were drawn.
The CAD-trained architect reads this as the tool failing to follow instructions. The probability-trained architect reads it as the tool doing exactly what it is supposed to do, and recognises that the actual work has arrived: which of these two interpretations better fits this project’s specific weight of constraints, this client’s risk profile, the studio’s position on procession-versus-performance?
That is not failure. That is the work being relocated.
What the work becomes
The discipline shifts from operating to evaluating.
We keep asking whether AI will replace the architect, as if the architect’s primary value was the manual production of outputs. That was never the deepest value. The architect’s deepest value has always been judgment about which of many defensible options to commit to — a task that probabilistic systems make more visible, not less necessary. When the model can produce twelve courtyards before lunch, the question of which one is no longer downstream. It is the entire concern.
In studios we’ve worked with, the practitioners who absorb this shift fastest already had a strong evaluative instinct. The tool reveals it; it does not produce it.
The standard frustrations are diagnostic. “It gave me a different answer the second time” is not a complaint about the tool. It is the architect noticing, for the first time, that they were never the one being asked to commit. The CAD-and-render workflow let them outsource the appearance of resolution to the software. The probability engine refuses to. It hands back a spread of plausible options and waits for the architect to do the thing the architect was always being paid to do.
Output has become abundant. Naming what to keep has become scarce.
The mistake that compounds
The category mistake is not just intellectual confusion. It compounds operationally. Architects who carry the deterministic mental model into a probabilistic system tend to do three things, each of which makes the tool less useful.
They read variation as error and try to fix it with more constraint, when variation is the design space they should be reading. They treat the first sample as the answer and escalate to longer prompts to make the tool “commit,” as if persistence could turn a probability engine into a deterministic one. And they outsource curation to the model by asking “which one is best?” — a question the model was never built to answer, because best is a judgment, not a probability.
Each is the same underlying error in a different costume. The system is being asked deterministic questions, and it cannot answer them, because it is not that kind of system.
In our workshops, most architects we meet in 2026 — three years into daily AI use — are still operating inside this mistake.
A door, not a summary
The category correction is the first move. The second is recognising that generative AI is itself not one thing — there are at least three distinct families of probability engine running underneath the chatbots and image tools we use, each with a different architecture, a different failure mode, and a different relationship to architectural work. For how the three families of generative AI actually differ from each other, read Part 2.
The instinct will be to ask: how do I prompt better? That is still the deterministic question in disguise. The harder question — what does AI expose about my judgment? — is where the series goes from here.
Same brief. Two valid futures. The architect picks.
The category mistake is correctable, but not by reading. It is corrected against your own live projects, in a room where the mental model gets repaired by use. We run a one-day workshop — the AI Design Director Protocol — for exactly this: the room where the deterministic instinct gets unlearned against the architect’s current work, and where the spread of plausible outputs starts to look like a design space rather than a malfunction.
Want to know more about the Protocol? Head to protocol.rbdsailab.com

Further reading
Three references hold up well as of the time of writing for the reader who wants to go deeper without slipping into engineering math:
• Andrej Karpathy’s [1hr Talk] Intro to Large Language Models — the cleanest one-hour overview by a credible technical educator.
• Stephen Wolfram’s What Is ChatGPT Doing… and Why Does It Work? — a precise mental model of next-token prediction. Demanding; rewards patience.
• Ethan Mollick’s One Useful Thing — consistently useful weekly reading on living with these systems at non-engineer literacy.
Sources
[1] Anthropic. On the Biology of a Large Language Model. 2025.
https://transformer-circuits.pub/2025/attribution-graphs/biology.html
I’m Sahil Tanveer of the RBDS AI Lab, where we explore the evolving intersection of AI and Architecture through design practice, research, and public dialogue. If today’s post sparked your curiosity, here’s where you can dive deeper:
Read my book – Delirious Architecture: Midjourney for Architects, a 330-page exploration of AI’s role in design → Get it here
Join the conversation – Our WhatsApp Channel AI in Architecture shares mind-bending updates on AI’s impact on design → Follow here
Learn with us – Our online course AI Fundamentals for Lighting Designers is power-packed with 17+hrs of video content through 17 lessons → Enroll Here
Explore free resources – Setup guides, tools, and experiments on our Gumroad
Watch & listen – Our YouTube channel blends education with architectural art
Discover RBDS AI Lab – Visit our website
Speaking & events – I speak at conferences and universities across India and beyond. Past talks here
📩 Enquiries: sahil@rbdsailab.com | Instagram
Might be your best article yet. I think it could be broken into segment - and released as chapters to become another book.